Amiga „Cluster“ with FPU
The flickering is much better, the picture was painted too often and the message loop was polled too seldom. Optimized this a little bit, now it happens very seldom. When I started this tests first I implemented a simple Speedtest which does the same calculation for one second and then count the successfully calculated pixels.
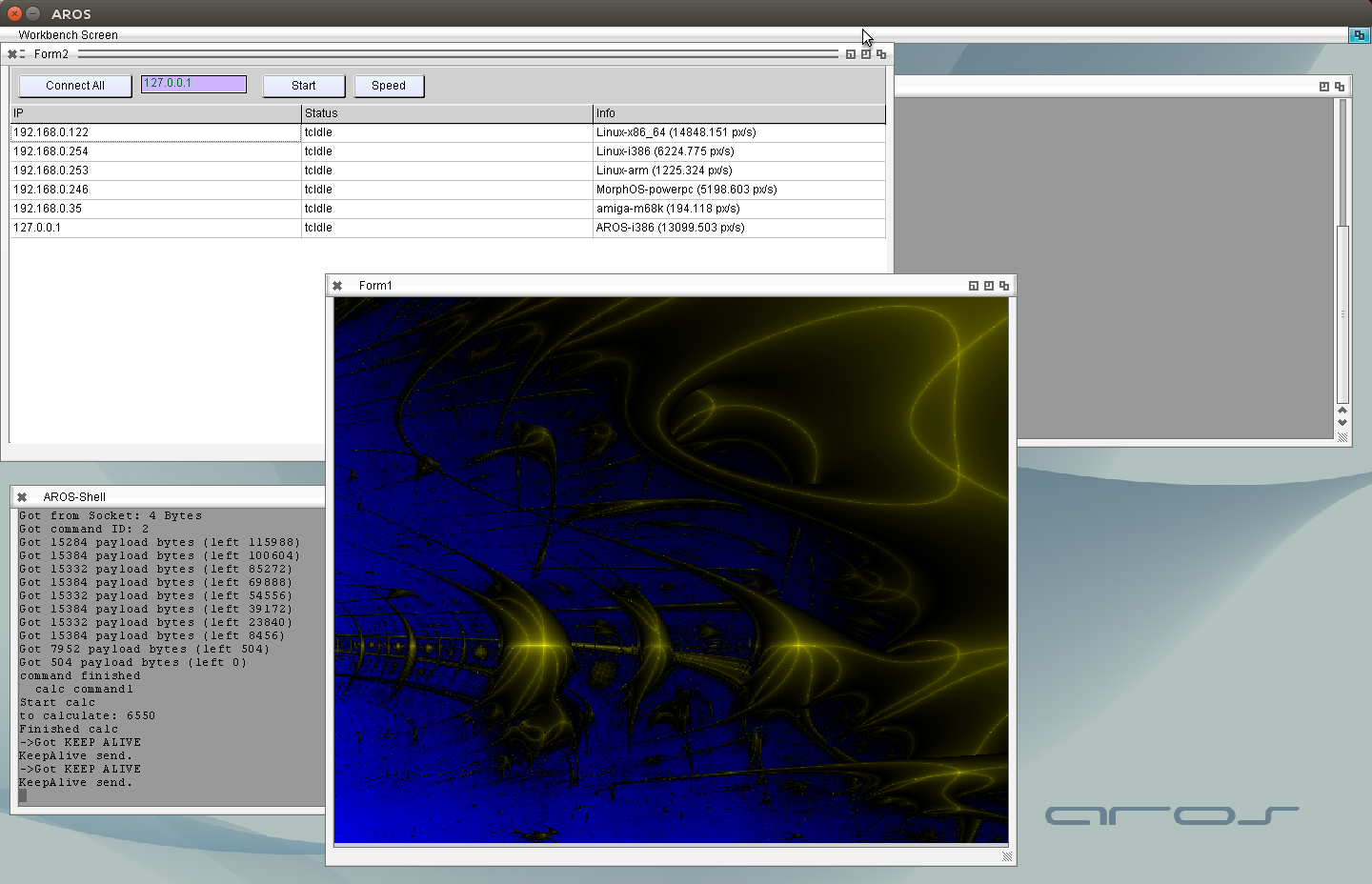
So of course would be nice to have it also in this graphical server and optimize the number of pixels requested from each client. I noticed the Amiga 1200 with 68060 50Mhz only finished 3-4 Pixels per second, I know it is slow, but that slow. (Besides this I’m surprised how fast the MacMini with MorphOS is, nice :-)) But then I remembered that the m68k freepascal does not use the FPU. By default it uses softfloat routines, which of course are very slow. But my automatic compiler server also compiles the FPU version of all units (enable at compiler with -Cf68881 and use FPU compiled units). The fpu compiled version is much, much faster now 200 px/s. Wow now the amiga really add some pixels to finished image. (Before also some, but less than a line ;-))
Speed test of the „Amiga Cluster“
It should be noted that the 192.168.0.122 (and 127.0.0.1) is a Computer with eight cores but only one is used here (in fact, two because 127.0.0.1 is AROS hosted on the same computer), I didn’t implement multicore threading.
Wow, impressive! Thank you for let us read so much success stories about your Freepascal port for AOS and „friends“. 🙂 Keep up the good work!